网络模型介绍
网络模型指含多隐层以及多层感知器的一种结构。神经网络的构建其实也可以看成一个点-线-面的构造过程。
点:即神经网络里许多计算节点(在神经网络里,称为神经元 Cell),
线:由一些节点再构成一层处理层(这一层就可以理解为对数据的某个
抽象表达),
面:由多个处理层构建起来就形成了一个神经网络。
这些点的连接方式不同就可以形成各种各样的不同的表达模型,即我们经常说的 cnn,Rnn,dnn 等
网络模型分类:大部分神经网络都可以用深度(depth)和连接结构(connection)来定义,笼统的说,神经网络也可以分为有监督的神经网络和无/半监督学习。
监督学习网络:循环网络(recurrent NN),卷积网络(convolutional NN),
无监督学习网络:深度生成模型,自编码器
循环网络 RNN:
RNN 的目的使用来处理序列数据。传统的神经网络没有考虑到时间的因素,也就是其并不能记忆之前存储的内容。而 Rnn 解决了这个问题,Rnn 包含循环网络,允许信息的持久化.
为了加强这种“记忆能力”,人们开发各种各样的变形体,如非常著
名的 Long Short-term Memory(LSTM),用于解决“长期及远距离的依赖
关系”
-
Long Short-term Memory(LSTM):
长期短期记忆 - 这是一种循环型神经网络(RNN),允许数据在网络中向前和向后流动。
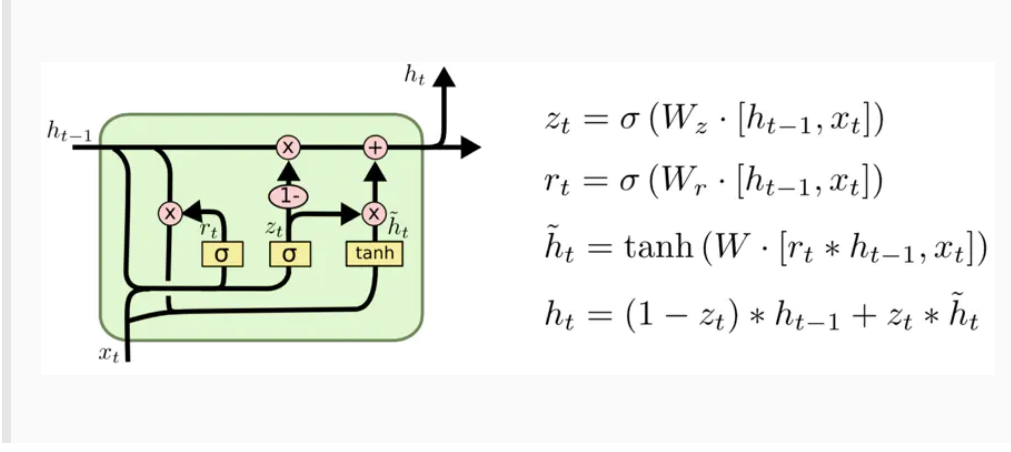
LSTM适合于处理和预测时间序列中间隔和延迟非常长的重要事件,隐马尔可夫模型和其他序列学习方法给LSTM带来了优势 。
-
双向循环网络(Bi-directional RNN)
是现阶段自然语言处理和语音分析中的重要模型。开发双向循环网络的原因是语言/语音的构成取决于上下文,即“现在”依托于“过去”和“未来”。单向的循环网络仅着重于从“过去”推出“现在”,而无法对“未来”的依赖性有效的建模。 -
应用场景
语音分析,文字分析,时间序列分析。主要的重点就是数据之间存在前后依赖关系,有序列关系。一般首选 LSTM,如果预测
对象同时取决于过去和未来,可以选择双向结构,如双向LSTM。
递归神经网络
- 简介:
递归神经网络(recursive neural network)是具有树状阶层结构且网络节点按其连接顺序对输入信息进行递归的人工神经网络(Artificial Neural Network, ANN),是深度学习(deep learning)算法之一 。递归神经网络(recursive neural network)提出于1990年,被视为循环神经网络(recurrent neural network)的推广 。当递归神经网络的每个父节点都仅与一个子节点连接时,其结构等价于全连接的循环神经网络。递归神经网络可以引入门控机制(gated mechanism)以学习长距离依赖 递归神经网络具有可变的拓扑结构且权重共享,被用于包含结构关系的机器学习任务,在自然语言处理(Natural Language Processing, NLP)领域有受到关注 。
- 递归神经网络和循环神经网络不同,它的计算图结构是树状结构而不是网状结构。递归循环网络的目标和循环网络相似,也是希望解决数据之间的长期依赖问题。而且其比较好的特点是用树状可以降低序列的长度,但和其他树状数据结构一样,如何构造最佳的树状结构如平衡树/平衡二叉树并不容易。
应用:
自然语言和自然场景解析 - 研究意义:
因为神经网络的输入层单元个数是固定的,因此必须用循环或者递归的方式来处理长度可变的输入。循环神经网络实现了前者,通过将长度不定的输入分割为等长度的小块,然后再依次的输入到网络中,从而实现了神经网络对变长输入的处理。egg:当我们处理一句话的时候,我们可以把一句话看作是词组成的序列,然后,每次向循环神经网络输入一个词,如此循环直至整句话输入完毕,循环神经网络将产生对应的输出。如此,我们就能处理任意长度的句子了。然而,有时候把句子看做是词的序列是不够的,比如下面这句话『两个外语学院的学生』:
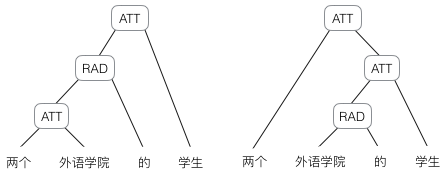
不同的语法解析树则对应了不同的意思。一个是『两个外语学院的/学生』,另一个是『两个/外语学院的学生』。
为了能够让模型区分出两个不同的意思,我们的模型必须能够按照树结构去处理信息,而不是序列,这就是递归神经网络的作用。当面对按照树/图结构处理信息更有效的任务时,递归神经网络通常都会获得不错的结果。
卷积网络 CNN
- 简介:
特殊的深层的神经网络模型,他的特殊型体现在两个方面,一方面他的神经元连接是非全连接的,另一方面同一层中某些神经元之间的连接的权重是共享的(即相同的)。卷积网络的精髓其实就是在多个空间位置上共享参数。 - 目前比较流行的卷积网络模型:
lenet , alexnet , Network in NetWork , VGG , Googlenet,Resnet - 应用场景:
虽然我们一般都把 CNN 和图片联系在一起,但事实上 CNN可以处理大部分格状结构化数据(Grid-like Data)。举个例子,图片的像素是二维的格状数据,时间序列在等时间上抽取相当于一维的的格状数据,而视频数据可以理解为对应视频帧宽度、高度、时间的三维数
深度信念网络(Deep Belief Neural Networks)
-
简介:
主要有两个部分: 1. 堆叠的受限玻尔兹曼机(Stacked RBM) 2. 一层普通的前馈网络。
本质上是在做逐层无监督学习,每次学习一层网络结构再逐步加深网络 -
具体过程:
DBN是由Hinton在2006年提出的一种概率生成模型, 由多个限制玻尔兹曼机(RBM)堆栈而成:
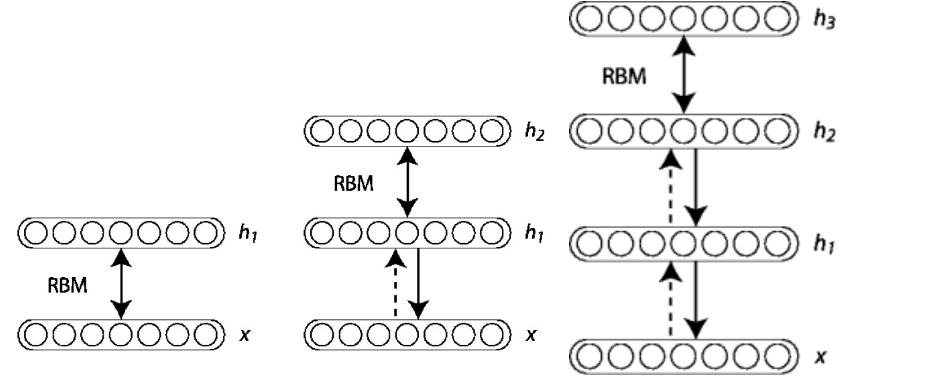
在训练时, Hinton采用了逐层无监督的方法来学习参数。首先把数据向量x和第一层隐藏层作为一个RBM, 训练出这个RBM的参数(连接x和h1的权重, x和h1各个节点的偏置等等), 然后固定这个RBM的参数, 把h1视作可见向量, 把h2视作隐藏向量, 训练第二个RBM, 得到其参数, 然后固定这些参数, 训练h2和h3构成的RBM…
在使用上述的逐层无监督方法学得节点之间的权重以及节点的偏置之后(亦即初始化), 可以在DBN的最顶层再加一层, 来表示我们希望得到的输出, 然后计算模型得到的输出和希望得到的输出之间的误差, 利用后向反馈的方法来进一步优化之前设置的初始权重。因为我们已经使用逐层无监督方法来初始化了权重值, 使其比较接近最优值, 解决了之前多层神经网络训练时存在的问题, 能够得到很好的效果。 -
应用场景:现在来说 DBN 更多是了解深度学习“哲学”和“思维模式”的一个手段,在实际应用中还是推荐 CNN/RNN 等,类似的深度玻尔兹曼机也有类似的特性但工业界使用较少
生成式对抗网络(Generative Adversarial Networks)
-
简介:
简单的说,GAN 训练两个网络:1. 生成网络用于生成图片使其与训练数据相似 2. 判别式网络用于判断生成网络中得到的图片是否是真的是训练数据还是伪装的数据。 -
应用:
应用场景:现阶段的 GAN 还主要是在图像领域比较流行,但很多人都认为它有很大的潜力大规模推广到声音、视频领域。
自编码器 Autoencoder
https://www.cnblogs.com/yifdu25/p/8268214.html
-
简介:
自编码器(autoencoder, AE)是一类在半监督学习和非监督学习中使用的人工神经网络(Artificial Neural Networks, ANNs),其功能是通过将输入信息作为学习目标,对输入信息进行表征学习(representation learning)。
自编码器包含编码器(encoder)和解码器(decoder)两部分 。
按学习范式,自编码器可以被分为收缩自编码器(undercomplete autoencoder)、正则自编码器(regularized autoencoder)和变分自编码器(Variational AutoEncoder, VAE),其中前两者是判别模型、后者是生成模型 。按构筑类型,自编码器可以是前馈结构或递归结构的神经网络。
自编码器具有一般意义上表征学习算法的功能,被应用于降维(dimensionality reduction)和异常值检测(anomaly detection)。包含卷积层构筑的自编码器可被应用于计算机视觉问题,包括图像降噪(image denoising) 、神经风格迁移(neural style transfer)等。 -
过程:
Autoencoder 主要有 2 个部分:1. 编码器(Encoder) 2. 解码器(Decoder)
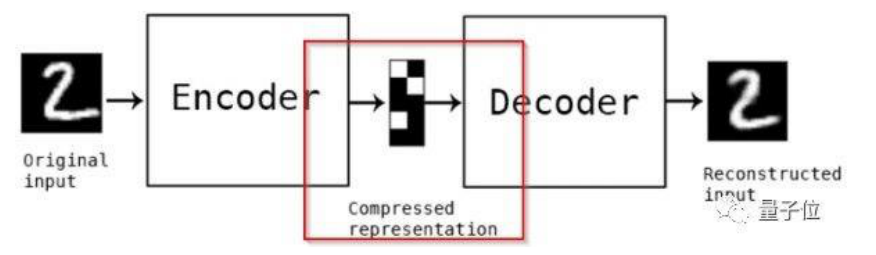
事实上我们真正学习到是中间的用红色标注的部分,即数在低维
度的压缩表示。评估自编码器的方法是重建误差,即输出的那个
数字 2 和原始输入的数字 2 之间的差别,当然越小越好,自编码
器也可以用来进行数据压缩(Data Compression),从原始数据中
提取最重要的特征。发现输入的那个数字 2 和输出的数字 2 略有
不同,这是因为数据压缩中的损失。 -
应用场景:
主要用于降维(Dimension Reduction),同时也有专门
用 于 去 除 噪 音 还 原 原 始 数 据 的 去 噪 编 码 器 (Denoising Autoencoder)